REgex in visual studio is really powerful to replace code. It is really same as php or perl regex, but you can do tag expressions as well.
I was copying some fields from edit page to detail page. I did not need all the validation messages,so i need to remove all that. I have to find each message and remove it manually. I had multiple pages to deal with,so I need something better than manual editing. Regex replace came to rescue. Of course, i have to try different expressions to match what i want. I copied here for your reference. Let say you have a code in edit page like this:
We are targeting validation message from start of the word to the end of parenthesis.
Syntax:
\ is regex escape character.
[^)] means all chars except right parenthesis
[] Brackets represent single character from inside whatever written in there. [A-Z] represent single char from A to Z. if you want to have more than one, you add special symbol after that.
It will look like this [A-Z]* to tell chars zero or more from A to Z.
In our example:
\@Html.ValidationMessageFor\([^)]* means get inside of the validation message until right parenthesis. We want to select all the syntax related to validation message.
Our final char right parenthesis is also escaped. With this expression, you can target something like:
and replace with empty string in my case or whatever you want.
Replace can also target selected expressions,so you can append your replacement text to the matched block.
Tag expression support can be usefull if you want to split camelcase field name into words.
if you want change this .NET MVC3 syntax :
to this:
You can set the target and replace as shown in the figure:
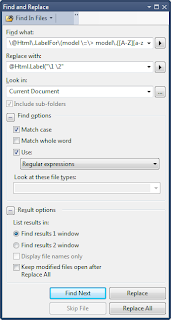
{} means tagged expression. We target those in replace block.
First target expression gets the first word with starting upper case and have one or more lowercase letters. Second expression is similar. Replace tag is:
If field is something like "ClaimClientID", you need to change the target syntax to this:
It is still targetting two expressions but it will take the remaining characters even if they are not lower case or numeric.
We don't need right parenthesis at the end. Our target expression is not matching that so it will stay there. You can play with these to create your own powerful regex in visual studio advanced replace menu.
I copied other options from visual studio help menu:
Regular Expressions for Find and Replace
I was copying some fields from edit page to detail page. I did not need all the validation messages,so i need to remove all that. I have to find each message and remove it manually. I had multiple pages to deal with,so I need something better than manual editing. Regex replace came to rescue. Of course, i have to try different expressions to match what i want. I copied here for your reference. Let say you have a code in edit page like this:
1: <div class="editor-label">
2: @Html.LabelFor(model => model.ClaimTax.ER_SUTA_Amt)
3: </div>
4: <div class="editor-field">
5: @Html.EditorFor(model => model.ClaimTax.ER_SUTA_Amt)
6: @Html.ValidationMessageFor(model => model.ClaimTax.ER_SUTA_Amt)
7: </div>
We are targeting validation message from start of the word to the end of parenthesis.
Syntax:
1: \@Html.ValidationMessageFor\([^)]*\)
\ is regex escape character.
[^)] means all chars except right parenthesis
[] Brackets represent single character from inside whatever written in there. [A-Z] represent single char from A to Z. if you want to have more than one, you add special symbol after that.
It will look like this [A-Z]* to tell chars zero or more from A to Z.
In our example:
\@Html.ValidationMessageFor\([^)]* means get inside of the validation message until right parenthesis. We want to select all the syntax related to validation message.
Our final char right parenthesis is also escaped. With this expression, you can target something like:
1: @Html.ValidationMessageFor(model => model.ClaimTax.ER_SUTA_Amt)
and replace with empty string in my case or whatever you want.
Replace can also target selected expressions,so you can append your replacement text to the matched block.
Tag expression support can be usefull if you want to split camelcase field name into words.
if you want change this .NET MVC3 syntax :
1: @Html.LabelFor(model => model.LastName)
to this:
1: @Html.Label("Last Name")
You can set the target and replace as shown in the figure:
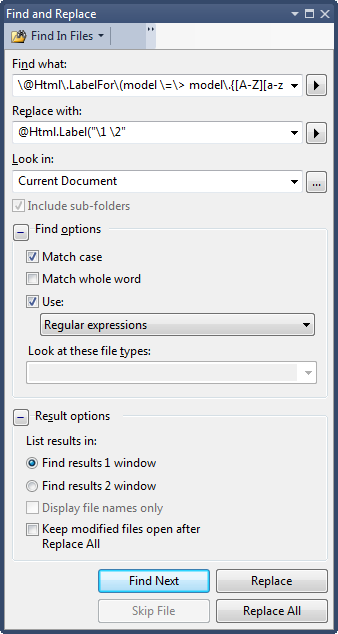
1: \@Html.LabelFor\(model \=\> model\.{[A-Z][a-z]+}{[A-Z][a-z]+}
{} means tagged expression. We target those in replace block.
First target expression gets the first word with starting upper case and have one or more lowercase letters. Second expression is similar. Replace tag is:
1: @Html.Label("\1 \2"
If field is something like "ClaimClientID", you need to change the target syntax to this:
1: \@Html.LabelFor\(model \=\> model\.{[A-Z][a-z]+}{[A-Z][a-z]+[^)]*}
It is still targetting two expressions but it will take the remaining characters even if they are not lower case or numeric.
We don't need right parenthesis at the end. Our target expression is not matching that so it will stay there. You can play with these to create your own powerful regex in visual studio advanced replace menu.
I copied other options from visual studio help menu:
Regular Expressions for Find and Replace
Expression
|
Syntax
|
Description
|
Example
|
Any
character |
.
|
Matches
any single character except a line break. |
a.o matches "aro"
in "around" and "abo" in "about" but not "acro" in "across". |
Zero or
more |
*
|
Matches
zero or more occurrences of the preceding expression, and makes all possible matches. |
a*b matches "b" in "bat" and "ab" in "about".
e.*e matches
the word "enterprise". |
One or
more |
Matches
at least one occurrence of the preceding expression. |
ac matches words that contain the letter "a" and at
least one instance of "c", such as "race", and "ace".
a. s matches the word "access".
| |
Beginning
of line |
^
|
Anchors
the match string to the beginning of a line. |
^car matches
the word "car" only when it appears as the first set of characters in a line of the editor. |
End of
line |
$
|
Anchors
the match string to the end of a line. |
end$ matches
the word "end" only when it appears as the last set of characters possible at the end of a line in the editor. |
Beginning
of word |
<
|
Matches
only when a word starts at this point in the text. |
<in matches
words such as "inside" and "into" that begin with the letters "in". |
End of
word |
>
|
Matches
only when a word ends at this point in the text. |
ss> matches words such as
"across" and "loss" that end with the letters "ss". |
Line
break |
\n
|
Matches
an operating system-independent line break. In a Replace expression, inserts a line break. |
End\nBegin matches the word "End" and
"Begin" only when "End" is the last string in a line and "Begin" is the first string in the next line.
In a
Replace expression,
Begin\nEnd replaces the word "End" with
"Begin" on the first line, inserts a line break, and then replaces the word "Begin" with the word "End". |
Any one
character in the set |
[]
|
Matches
any one of the characters in the []. To specify a range of characters, list the starting and ending characters separated by a dash (-), as in [a-z]. |
be[n-t] matches "bet" in "between",
"ben" in "beneath", and "bes" in "beside" but not "bel" in "below". |
Any one
character not in the set |
[^...]
|
Matches
any character that is not in the set of characters that follows the ^. |
be[^n-t] matches "bef" in
"before", "beh" in "behind", and "bel" in "below", but not "ben" in "beneath". |
Or
|
|
|
Matches
either the expression before or the one after the OR symbol (|). Mostly used in a group. |
(sponge|mud) bath matches "sponge bath" and
"mud bath." |
Escape
|
\
|
Matches
the character that follows the backslash (\) as a literal. This lets you find the characters that are used in regular expression notation, such as { and ^. |
\^ searches
for the ^ character. |
Tagged
expression (or backreference) |
{}
|
Matches
text that is tagged with the enclosed expression. |
zo{1} matches
"zo1" in "Alonzo1 "and "Gonzo1", but not "zo" in "zone". |
C/C
Identifier |
:i
|
Shorthand
for the expression ([a-zA-Z_$][a-zA-Z0-9_$]*). |
Matches
any possible C/C identifier. |
Quoted
string |
:q
|
Shorthand
for the expression (("[^"]*")|('[^']*')), which matches all characters that are enclosed in double or single quotation marks, and also the quotation marks themselves. |
:q matches "test quote" and 'test quote' but not
the 't of can't. |
Space or
Tab |
:b
|
Matches
either space or tab characters. |
Public:bInterface matches
the phrase "Public Interface" in text. |
Integer
|
:z
|
Shorthand
for the expression ([0-9] ), which matches any combination of numeric characters. |
Matches
any integer, such as "1", "234", "56", and so on. |
The list of all regular expressions that are valid in Find and
Replace operations is longer than can be displayed in the Expression
Builder. Although the following regular expressions do not appear in the Expression
Builder, you can use them in the Find what or Replace with fields.
Replace operations is longer than can be displayed in the Expression
Builder. Although the following regular expressions do not appear in the Expression
Builder, you can use them in the Find what or Replace with fields.
Expression
|
Syntax
|
Description
|
Example
|
Minimal,
zero or more |
@
|
Matches
zero or more occurrences of the preceding expression, and matches as few characters as possible. |
e.@e matches "ente" and "erprise"
in "enterprise", but not the full word "enterprise". |
Minimal,
one or more |
#
|
Matches
one or more occurrences of the preceding expression, and matches as few characters as possible. |
ac# matches words that contain the letter "a" and
at least one instance of "c", such as "ace".
a.#s matches "acces" in the
word "access". |
Repeat n times
|
^ n
|
Matches n occurrences
of the preceding expression. |
[0-9]^4 matches any 4-digit sequence.
|
Grouping
|
()
|
Lets you group a set of expressions together. If you want to search
for two different expressions in a single search, you can use the Grouping expression to combine them. |
If you
want to search for - [a-z][1-3] or - [1-10][a-z], you would combine them: ([a-z][1-3]) | ([1-10][a-z]). |
nth
tagged text |
\ n
|
In a
Find or Replace expression, indicates the text that is matched by the nth tagged expression, where n is a number from 1 to 9.
In a
Replace expression, \0 inserts the complete matched text. |
If you
search for a{[0-9]} and replace with \1, all occurrences of "a" followed by a digit are replaced by the digit it follows. For example, "a1" is replaced by "1" and similarly "a2" is replaced by "2". |
Right-justified
field |
\( w, n)
|
In a
Replace expression, right-justifies the nth tagged expression in a field at least wcharacters wide. |
If you
search for a{[0-9]} and replace with \(10,1), the occurrences of "a n" are replaced by the integer and right-justified by 10 spaces. |
Left-justified
field |
\(- w, n)
|
In a
Replace expression, left-justifies the nth tagged expression in a field at least wcharacters wide. |
If you
search for a{[0-9]} and replace with \(-10,1), the occurrences of "a n" are replaced by the integer and left-justified by 10 spaces. |
Prevent
match |
~(X)
|
Prevents
a match when X appears at this point in the expression. |
real~(ity) matches the
"real" in "realty" and "really," but not the "real" in "reality." |
Alphanumeric
character |
:a
|
Matches
the expression ([a-zA-Z0-9]). |
Matches
any alphanumeric character, such as "a", "A", "w", "W", "5", and so on. |
Alphabetic
character |
:c
|
Matches
the expression ([a-zA-Z]). |
Matches
any alphabetical character, such as "a", "A", "w", "W", and so on. |
Decimal
digit |
:d
|
Matches
the expression ([0-9]). |
Matches
any digit, such as "4" and "6". |
Hexadecimal
digit |
:h
|
Matches
the expression ([0-9a-fA-F] ). |
Matches
any hexadecimal number, such as "1A", "ef", and "007". |
Rational
number |
:n
|
Matches
the expression (([0-9] .[0-9]*)|([0-9]*.[0-9] )|([0-9] )). |
Matches
any rational number, such as "2007", "1.0", and ".9". |
Alphabetic
string |
:w
|
Matches
the expression ([a-zA-Z] ). |
Matches
any string that contains only alphabetical characters. |
Escape
|
\e
|
Unicode
U 001B. |
Matches
the "Escape" control character. |
Bell
|
\g
|
Unicode
U 0007. |
Matches
the "Bell" control character. |
Backspace
|
\h
|
Unicode
U 0008. |
Matches
the "Backspace" control character. |
Tab
|
\t
|
Unicode
U 0009. |
Matches
a tab character. |
Unicode
character |
\x####
or \u#### |
Matches
a character given by Unicode value where #### is hexadecimal digits. You can specify a character that is outside the Basic Multilingual Plane (that is, a surrogate) with the ISO 10646 code point or with two Unicode code points that give the values of the surrogate pair. |
\u0065 matches
the character "e". |
No comments:
Post a Comment
Hey!
Let me know what you think?