You can import namespaces at the beginning of the page and reference them directly.
<%@ Import Namespace="myapp.Controllers" %>
If you have a Product controller in myapp, you can reference this directly without writing myapp.Controllers.Product.
Thursday, November 25, 2010
Friday, November 19, 2010
How to trigger event for Truncate action in MS SQL
NOTE:
?????
I guess it is not possible to trigger event for Truncate,but prevent it.
From msdn:
TRUNCATE TABLE cannot activate a trigger because the operation does not log individual row deletions. We can prevent truncate action,if we create a view WITH SCHEMABINDING.
If we don't use truncate on the application level, we will be dealing with only delete command. It is easy to prevent that with Instead Of Trigger.
?????
I guess it is not possible to trigger event for Truncate,but prevent it.
From msdn:
TRUNCATE TABLE cannot activate a trigger because the operation does not log individual row deletions. We can prevent truncate action,if we create a view WITH SCHEMABINDING.
If we don't use truncate on the application level, we will be dealing with only delete command. It is easy to prevent that with Instead Of Trigger.
Friday, October 29, 2010
ASP MVC IIS not running
Hey,
I had the same problem on IIS 7.5 with MVC 1. I fixed the problem and listed some steps here:
I had the same problem on IIS 7.5 with MVC 1. I fixed the problem and listed some steps here:
 |
| Figure-1:Install other IIS options |
- Read other normal IIS config steps
- If you dont see Asp.Net tab in config option, you need to register asp.net
- %windir%\Microsoft.NET\
Framework\v2.0.50727\aspnet_ regiis.exe -i - You need to check add-on features to install some other components to make IIS work. Installing them solves most of the problem. Redirect is off by default. Go to control panel ->programs-> Windows components part as show on Figure-1. If you don't see your aspx pages, it might be missing .net integration.
- Create your app and add simple html, asp pages for testing
- if it is showing default app, you need to remove that application
- You may need to start and stop application to make it work
- Change app pool identity to local system and give permissions at your database to access your tables for this user
- Allow all users for .net authorization
- It will work after these steps. If not check these:
- You may need to check connection strings to make sure you are connecting to the right sql instance
- Permission problem: You may need to give permission to web folders for application identity. If you change that to something else, add that user to list and give permissions.
Saturday, August 7, 2010
notes about xml processing in sql server
----working with xml data
--retrieving relational data as xml
--passing data a xml
--storing and querying actual
use AdventureWorks;
select
c.CustomerID,
c.AccountNumber,
c.CustomerType
from sales.Customer as c
where c.CustomerID in (1,2) ;
select soh.CustomerID,
soh.SalesOrderID,
soh.OrderDate,
soh.ShipDate
from Sales.SalesOrderHeader as soh
where soh.CustomerID in (1,2);
--instead use join query
select c.customerid , c.accountnumber, c.customertype,
soh.SalesPersonID, soh.OrderDate, soh.ShipDate
from
Sales.Customer as c left outer join
Sales.SalesOrderHeader as soh on soh.CustomerID = c.CustomerID
where c.CustomerID in (1,2)
--xml
select c.customerid as "@Id"
, c.accountnumber as "@AccountNumber"
, c.customertype as "@Type"
,(
SELECT
soh.SalesOrderID as "@Id"
,soh.OrderDate as "@OrderDate"
, soh.ShipDate as "@ShipDate"
from Sales.SalesOrderHeader as soh
where soh.CustomerID = c.CustomerID
for XML Path('Order') , TYPE
) as "Orders"
from
Sales.Customer as c
where c.CustomerID in (1,2)
FOR XML PATH('Customer'), ROOT('Customers');
---
USe AdventureWorks;
go
select
p.ProductID as "@Id",
p.Name as "Info/@Name",
p.ListPrice as "Info/@Listprice",
(
select
sod.SalesOrderID as "@Orderid",
sod.OrderQty as "@QTY",
soh.OrderDate as "@date",
soh.CustomerID as "@customerid"
from Sales.SalesOrderHeader soh
inner join Sales.SalesOrderDetail as sod
on sod.SalesOrderID = soh.SalesOrderID
where sod.ProductID = p.ProductID
for XML path('Ordersub'), TYPE
)
from Production.Product as p
where p.ProductID = 707
for xml path('Product');
---master order and details
select
p.ProductID as "@Id",
p.Name as "Info/@Name",
p.ListPrice as "Info/@Listprice",
(
select
sod.SalesOrderID as "@Orderid",
sod.OrderQty as "@QTY",
soh.OrderDate as "@date",
soh.CustomerID as "@customerid"
from Sales.SalesOrderHeader soh
inner join Sales.SalesOrderDetail as sod
on sod.SalesOrderID = soh.SalesOrderID
where sod.ProductID = p.ProductID
for XML path('Ordersub'), TYPE
)
from Sales.SalesOrderHeader soh
where p.ProductID = 707
for xml path('Product');
--list top 10 orders with amount max
--
select top 1
sh.SalesOrderID as "@ID",
sh.OrderDate as "@OrderDate",
sh.ShipDate as "@ShipDate",
sh.Status as "@Status",
sh.CustomerID as "@CustomerID",
sh.SalesPersonID as "@SalesPersonID",
sh.Totaldue as "@TotalDue",
(select top 5
sod.ProductID,
sod.OrderQty,
sod.LineTotal
from
Sales.SalesOrderDetail sod
where sod.SalesOrderID = sh.SalesOrderID
order by sod.LineTotal desc
for XML path('Ordersub'), TYPE
)
from Sales.SalesOrderHeader sh
order by sh.TotalDue desc
for xml path('Sales') ,root('SalesTop10')
;
--read test
Declare @myxml XML
set @myxml = N'
969
21
26159.208075
966
16
19930.825200
954
16
12206.438400
892
23
12064.488425
967
6
8582.652000
';
select @myxml.query('
{for $o in /SalesTop10/Sales/Ordersub
where $o/OrderQty > 16
return
}
')
/* output
*/
---all of them in properties
select top 1
sh.SalesOrderID as "@ID",
sh.OrderDate as "@OrderDate",
sh.ShipDate as "@ShipDate",
sh.Status as "@Status",
sh.CustomerID as "@CustomerID",
sh.SalesPersonID as "@SalesPersonID",
sh.Totaldue as "@TotalDue",
(select top 5
sod.ProductID as "@ProductID",
sod.OrderQty as "@QTY",
sod.LineTotal as "LineTotal"
from
Sales.SalesOrderDetail sod
where sod.SalesOrderID = sh.SalesOrderID
order by sod.LineTotal desc
for XML path('Ordersub'), TYPE
)
from Sales.SalesOrderHeader sh
order by sh.TotalDue desc
for xml path('Sales') ,root('SalesTop1')
;
declare @otherxml XML
set @otherxml = N'
26159.208075
19930.825200
12206.438400
12064.488425
8582.652000
';
---reshape results with xquery
SELECT (SELECT top 10 * FROM Sales.Customer as Customers FOR XML AUTO,type ).query(
'{
for $c in /Customers
return
}')
---
;
create schema TestXml;
go
create table TestXml.Messages
(
MessageID int identity primary key,
FromUser nvarchar(50) not null,
Message nvarchar(max) not null,
CreatedDateTime datetime2 not null default sysdatetime()
);
--proc to insert data from xml input
create procedure TestXml.spMessageAddMany
@Message XML
as
Begin
set nocount on;
Insert TestXml.Messages (FromUser, Message)
Select
tab.col.value('@FromUser', 'NVARCHAR(50)'),
tab.col.value('text()[1]', 'NVARCHAR(max)')
from @Message.nodes('/Messages/Message') as tab(col);
end
---now insert some xml messages
EXEC TestXml.spMessageAddMany @Message = N'
Naber nasil?
Naber nasil2?
Naber nasil3?
';
Select * from TestXml.Messages;
--working with xml stored in xml variable or column
EXIST METHOd
select top 1 Demographics
from Sales.Individual
with xmlnamespaces(default
'http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/IndividualSurvey')
select COUNT(*)
from Sales.Individual
where Demographics.exist(
'/IndividualSurvey/Occupation') = 1
with xmlnamespaces(default
'http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/IndividualSurvey')
select COUNT(*)
from Sales.Individual
where Demographics.exist(
'/IndividualSurvey/TotalPurchaseYTD[xs:decimal(.) > 8000]') = 1
with xmlnamespaces(default
'http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/IndividualSurvey')
select COUNT(*)
from Sales.Individual
where Demographics.exist(
'/IndividualSurvey/TotalPurchaseYTD[xs:decimal(.) > 8000]') = 1
---Extract Properties from XML Variable
DECLARE @xVar XML
SET @xVar =
'
Michael
Howard
David
LeBlanc
2David
2LeBlanc
3LeBlanc
39.99
'
SELECT nref.value('first-name[1]', 'nvarchar(50)') FirstName, --get first element [1]
nref.value('last-name[1]', 'nvarchar(50)') LastName
FROM @xVar.nodes('//author') AS R(nref)
WHERE nref.exist('.[first-name != "David"]') = 1
--value method
with xmlnamespaces(default
'http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/IndividualSurvey')
select SUM(demographics.value('count(/IndividualSurvey)', 'INT')) AS NumberofISurveys
from Sales.Individual
--TotalPurchaseYTD
with xmlnamespaces(default
'http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/IndividualSurvey')
select SUM(demographics.value('sum(/IndividualSurvey/TotalPurchaseYTD)', 'decimal(10,2)')) AS NumberofISurveys
from Sales.Individual
--avg TotalChildren
with xmlnamespaces(default
'http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/IndividualSurvey')
select (demographics.value('sum(/IndividualSurvey/TotalChildren)', 'decimal(10,2)')) AS NumberofISurveys
from Sales.Individual
---NODES
declare @orders xml;
set @orders = N'
a
b
c
';
SELECT nref.value('Order[1]', 'nvarchar(50)') rowOrder --get first element [1]
,nref.value('Product[1]', 'nvarchar(50)') rowOrderProduct
FROM @orders.nodes('//Orders') AS R(nref)
DECLARE @T varchar(max)
SET @T =
'
'
DECLARE @X xml
SET @X = CAST(@T as xml)
SELECT
YY.t.value('(@FieldRowId)[1]', 'int') as FieldID,
YY.t.value('(Items/Item/@Name)[1]', 'varchar(max)') as "Name",
YY.t.value('(Attributes/Attribute/@ID)[1]', 'int') as AttributeID
FROM @X.nodes('/root/Field') as YY(t)
--retrieving relational data as xml
--passing data a xml
--storing and querying actual
use AdventureWorks;
select
c.CustomerID,
c.AccountNumber,
c.CustomerType
from sales.Customer as c
where c.CustomerID in (1,2) ;
select soh.CustomerID,
soh.SalesOrderID,
soh.OrderDate,
soh.ShipDate
from Sales.SalesOrderHeader as soh
where soh.CustomerID in (1,2);
--instead use join query
select c.customerid , c.accountnumber, c.customertype,
soh.SalesPersonID, soh.OrderDate, soh.ShipDate
from
Sales.Customer as c left outer join
Sales.SalesOrderHeader as soh on soh.CustomerID = c.CustomerID
where c.CustomerID in (1,2)
--xml
select c.customerid as "@Id"
, c.accountnumber as "@AccountNumber"
, c.customertype as "@Type"
,(
SELECT
soh.SalesOrderID as "@Id"
,soh.OrderDate as "@OrderDate"
, soh.ShipDate as "@ShipDate"
from Sales.SalesOrderHeader as soh
where soh.CustomerID = c.CustomerID
for XML Path('Order') , TYPE
) as "Orders"
from
Sales.Customer as c
where c.CustomerID in (1,2)
FOR XML PATH('Customer'), ROOT('Customers');
---
USe AdventureWorks;
go
select
p.ProductID as "@Id",
p.Name as "Info/@Name",
p.ListPrice as "Info/@Listprice",
(
select
sod.SalesOrderID as "@Orderid",
sod.OrderQty as "@QTY",
soh.OrderDate as "@date",
soh.CustomerID as "@customerid"
from Sales.SalesOrderHeader soh
inner join Sales.SalesOrderDetail as sod
on sod.SalesOrderID = soh.SalesOrderID
where sod.ProductID = p.ProductID
for XML path('Ordersub'), TYPE
)
from Production.Product as p
where p.ProductID = 707
for xml path('Product');
---master order and details
select
p.ProductID as "@Id",
p.Name as "Info/@Name",
p.ListPrice as "Info/@Listprice",
(
select
sod.SalesOrderID as "@Orderid",
sod.OrderQty as "@QTY",
soh.OrderDate as "@date",
soh.CustomerID as "@customerid"
from Sales.SalesOrderHeader soh
inner join Sales.SalesOrderDetail as sod
on sod.SalesOrderID = soh.SalesOrderID
where sod.ProductID = p.ProductID
for XML path('Ordersub'), TYPE
)
from Sales.SalesOrderHeader soh
where p.ProductID = 707
for xml path('Product');
--list top 10 orders with amount max
--
select top 1
sh.SalesOrderID as "@ID",
sh.OrderDate as "@OrderDate",
sh.ShipDate as "@ShipDate",
sh.Status as "@Status",
sh.CustomerID as "@CustomerID",
sh.SalesPersonID as "@SalesPersonID",
sh.Totaldue as "@TotalDue",
(select top 5
sod.ProductID,
sod.OrderQty,
sod.LineTotal
from
Sales.SalesOrderDetail sod
where sod.SalesOrderID = sh.SalesOrderID
order by sod.LineTotal desc
for XML path('Ordersub'), TYPE
)
from Sales.SalesOrderHeader sh
order by sh.TotalDue desc
for xml path('Sales') ,root('SalesTop10')
;
--read test
Declare @myxml XML
set @myxml = N'
';
select @myxml.query('
{for $o in /SalesTop10/Sales/Ordersub
where $o/OrderQty > 16
return
}
')
/* output
*/
---all of them in properties
select top 1
sh.SalesOrderID as "@ID",
sh.OrderDate as "@OrderDate",
sh.ShipDate as "@ShipDate",
sh.Status as "@Status",
sh.CustomerID as "@CustomerID",
sh.SalesPersonID as "@SalesPersonID",
sh.Totaldue as "@TotalDue",
(select top 5
sod.ProductID as "@ProductID",
sod.OrderQty as "@QTY",
sod.LineTotal as "LineTotal"
from
Sales.SalesOrderDetail sod
where sod.SalesOrderID = sh.SalesOrderID
order by sod.LineTotal desc
for XML path('Ordersub'), TYPE
)
from Sales.SalesOrderHeader sh
order by sh.TotalDue desc
for xml path('Sales') ,root('SalesTop1')
;
declare @otherxml XML
set @otherxml = N'
';
---reshape results with xquery
SELECT (SELECT top 10 * FROM Sales.Customer as Customers FOR XML AUTO,type ).query(
'
for $c in /Customers
return
}')
---
;
create schema TestXml;
go
create table TestXml.Messages
(
MessageID int identity primary key,
FromUser nvarchar(50) not null,
Message nvarchar(max) not null,
CreatedDateTime datetime2 not null default sysdatetime()
);
--proc to insert data from xml input
create procedure TestXml.spMessageAddMany
@Message XML
as
Begin
set nocount on;
Insert TestXml.Messages (FromUser, Message)
Select
tab.col.value('@FromUser', 'NVARCHAR(50)'),
tab.col.value('text()[1]', 'NVARCHAR(max)')
from @Message.nodes('/Messages/Message') as tab(col);
end
---now insert some xml messages
EXEC TestXml.spMessageAddMany @Message = N'
';
Select * from TestXml.Messages;
--working with xml stored in xml variable or column
EXIST METHOd
select top 1 Demographics
from Sales.Individual
with xmlnamespaces(default
'http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/IndividualSurvey')
select COUNT(*)
from Sales.Individual
where Demographics.exist(
'/IndividualSurvey/Occupation') = 1
with xmlnamespaces(default
'http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/IndividualSurvey')
select COUNT(*)
from Sales.Individual
where Demographics.exist(
'/IndividualSurvey/TotalPurchaseYTD[xs:decimal(.) > 8000]') = 1
with xmlnamespaces(default
'http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/IndividualSurvey')
select COUNT(*)
from Sales.Individual
where Demographics.exist(
'/IndividualSurvey/TotalPurchaseYTD[xs:decimal(.) > 8000]') = 1
---Extract Properties from XML Variable
DECLARE @xVar XML
SET @xVar =
'
'
SELECT nref.value('first-name[1]', 'nvarchar(50)') FirstName, --get first element [1]
nref.value('last-name[1]', 'nvarchar(50)') LastName
FROM @xVar.nodes('//author') AS R(nref)
WHERE nref.exist('.[first-name != "David"]') = 1
--value method
with xmlnamespaces(default
'http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/IndividualSurvey')
select SUM(demographics.value('count(/IndividualSurvey)', 'INT')) AS NumberofISurveys
from Sales.Individual
--TotalPurchaseYTD
with xmlnamespaces(default
'http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/IndividualSurvey')
select SUM(demographics.value('sum(/IndividualSurvey/TotalPurchaseYTD)', 'decimal(10,2)')) AS NumberofISurveys
from Sales.Individual
--avg TotalChildren
with xmlnamespaces(default
'http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/IndividualSurvey')
select (demographics.value('sum(/IndividualSurvey/TotalChildren)', 'decimal(10,2)')) AS NumberofISurveys
from Sales.Individual
---NODES
declare @orders xml;
set @orders = N'
';
SELECT nref.value('Order[1]', 'nvarchar(50)') rowOrder --get first element [1]
,nref.value('Product[1]', 'nvarchar(50)') rowOrderProduct
FROM @orders.nodes('//Orders') AS R(nref)
DECLARE @T varchar(max)
SET @T =
'
'
DECLARE @X xml
SET @X = CAST(@T as xml)
SELECT
YY.t.value('(@FieldRowId)[1]', 'int') as FieldID,
YY.t.value('(Items/Item/@Name)[1]', 'varchar(max)') as "Name",
YY.t.value('(Attributes/Attribute/@ID)[1]', 'int') as AttributeID
FROM @X.nodes('/root/Field') as YY(t)
Saturday, July 17, 2010
How to call stored procs from User Defined Functions (udf) in SQL Server
If you want to use stored procs from your functions , it is not possible with simple "exec sp_myproc".
You can use openquery to call your server as linked server and execute stored procs.
You need to run some commands before running openquery.
Step-1: enable openquery
---open query to have access to stored procs within functions
--add your server as linked server
sp_addlinkedserver @server = 'LOCALSERVER', @srvproduct = '', @provider = 'SQLOLEDB', @datasrc = @@servername
You can use openquery to call your server as linked server and execute stored procs.
You need to run some commands before running openquery.
Step-1: enable openquery
---open query to have access to stored procs within functions
--add your server as linked server
sp_addlinkedserver @server = 'LOCALSERVER', @srvproduct = '', @provider = 'SQLOLEDB', @datasrc = @@servername
Step-2: enable data access
EXEC sp_serveroption 'OMER-PC', 'DATA ACCESS', TRUE
---Check access
EXEC sp_serveroption 'OMER-PC', 'DATA ACCESS', TRUE
---Check access
Step-3: Select * from openquery(LOCALSERVER, 'Exec sp_who')
This query should return some results. Openquery does not work for every stored proc. You need to look into the details.
Some simple examples:
1)--inline table function calling stored proc
-----------------------------------------------------------
create FUNCTION Test.udfCallProcInline()
returns table
AS
return
select * from openquery(LOCALSERVER, 'Exec sys.sp_tables')
GO
Some simple examples:
1)--inline table function calling stored proc
-----------------------------------------------------------
create FUNCTION Test.udfCallProcInline()
returns table
AS
return
select * from openquery(LOCALSERVER, 'Exec sys.sp_tables')
GO
--------------------------------------------------------------
You can call your function as normal udfs:
select * from Test.udfCallProcInline()
It is also possible to make joins and select columns from the results. You don't need to know column data types here.
2-)-multi statement function
--you may need to check column data types here
CREATE FUNCTION Test.udfCallAProc2()
returns @mytable table
(table_qualifier varchar(50),
table_owner varchar(50),
table_name varchar(50),
table_type varchar(50),
remarks varchar(255)
)
AS
begin
insert @mytable
select * from openquery(LOCALSERVER, 'Exec sys.sp_tables')
return
end
GO
select * from Test.udfCallAProc2()
----More examples....later...
Tuesday, June 22, 2010
Recommended Software Related Tools
Source Control and Bug track:
http://www.mantisbt.org/ , Mantis: Open source bug tracking system for multiple projects. It is free!
http://subversion.tigris.org/ , Subversion: Open source code repository and code control. Multiplatform and feature rich.
Windows Administration:
http://www.SysInternals.com, Microsoft acquired Sysinternals in July, 2006. Whether you’re an IT Pro or a developer, you’ll find Sysinternals utilities to help you manage, troubleshoot and diagnose your Windows systems and applications.
Web Development:
FireBug, Excellent addon tool for Fire Fox. You should have this.
NotePad++ Very good geneal purpose text editor.
WAMP Apache, MySQL, PHP on Windows. Single install with utilities if you don't want to mess with configs.
Desktop Apps:
7-Zip, file compresison, multiple formats, open source.
FileZilla, my FTP
KLite Codec Pack, codecs.
Portable Apps, you can carry your favorite portable programs in a USB drive. Use any USB flash drive, portable hard drive, iPod/MP3 player, etc
Interesting:
http://eyeos.org/ open source web OS. There are others out there, but this is Open Source and apears stable.
Content Management Systems:
CMS Made Simple: It is really simple and powerful. You can add code snippets inside layouts and it is evaluated in run time. It has admin menu to change layouts and styles. you can also edit them. You can install different Modules or develop your own module. It has good level of supporting documentation.
Thursday, June 10, 2010
FREE
FREE ADVICE!
What happens if you delete default database for a user in sql server?
--You will get an error msg as : Cannot open user default database
--Easy solution:
1- Click options in login window




What happens if you delete default database for a user in sql server?
--You will get an error msg as : Cannot open user default database
--Easy solution:
1- Click options in login window
Login Screen in SQL Server Management Studio
2-Set database to master or model

Change database for connection
3-This will fix your login problem. Next step is to find your default database and change that. It is normally located in security> logins> your loginname

Find your Login settings in security tab
4-Change your default database if it is not changed.

Now, you can fix the problem with your default database. Here is the cause of the problem from Mic:
The user default database is unavailable at the time of connection. It is possible that the database:
- Is in suspect mode.
- No longer exists.
- Is in single user mode and the only available connection is already being used by someone else or by something else.
- Has been detached.
- Has been set to the RESTRICTED_USER state.
- Is offline.
- Is set to emergency status.
- Does not have the login account mapped to a user or the user has been denied access.
- Is part of a database mirror.
Saturday, May 15, 2010
Eclipse Php Zend Debugger
How to Debug PhP Code in ECLIPSE?
If you want to see variable values with mouse over and change them to see the effect in your program without echo statements, you need debugging. You can follow the steps below to set up a php editor with debugging. You can email me for questions.
If you want to see variable values with mouse over and change them to see the effect in your program without echo statements, you need debugging. You can follow the steps below to set up a php editor with debugging. You can email me for questions.
- Install apache server
- Install Php from www.php.net
- Select all necessary items such as mysql, openssl, dba
- Download ZEND plugins for eclipse
- Copy zenddebugger.dll to PHP directory
- Add these to your php.ini file
zend_extension_ts=.\ZendDebugger.dll
zend_debugger.allow_hosts= 127.0.0.1
zend_debugger.expose_remotely=always
You may want to run phpinfo() script to see your actual php.ini file. You may have one copy at C:Windows directory.
4. Download Eclipse php editor with debugger. It will show you xdebug and zend for debugging.
5. Setup your work directory
6. Configure your debug options: it may launch at http://localhost. This is fine for the default settings.
7. Restart apache server after changing php.ini file
8. When you run in debug mode, Eclipse will ask you to load in perspective show detail debug screen
9. If you get error about php.ini directives, you should check you php.ini file. You can add phpinfo(); command line to list all properties of PHP. It will show you the address of php.ini file.
Summary: If you see zend debugger properties in your PHP property list, you have the debugging. Disable Xdebug if you have that. Zend and Xdebug may not work properly at the same time.
I am happy to have debugging in php. I guess no more "echo this echo that"
Best Regards,
Thursday, May 13, 2010
ASP Hosting
I am looking for asp hosting. Most of the hosting providers are offering similar services.
Check the list:
http://www.hosting-review.com/hosting-directory/top-10-lists/Top-10-ASP-Hosting-Companies.shtml
IX Web Hosting looks good with the low price tag.
1-How much does it cost to use asp hosting with sql server 2008?
--It looks like with 36 month plan, they charge around 10$ /month at IX web hosting.
2-Reliability ?
3-Support ?
4-Speed
5-Bandwidth limits
Check the list:
http://www.hosting-review.com/hosting-directory/top-10-lists/Top-10-ASP-Hosting-Companies.shtml
IX Web Hosting looks good with the low price tag.
1-How much does it cost to use asp hosting with sql server 2008?
--It looks like with 36 month plan, they charge around 10$ /month at IX web hosting.
2-Reliability ?
3-Support ?
4-Speed
5-Bandwidth limits
I will look into more details about this...Let me know your favorite Hosting provider for Windows!!!
Another info: http://www.dotnetpanel.com/ is open source now. You can download that and use it for hosting management.
Tuesday, April 27, 2010
Transaction and Locks in MS SQL 2008
Today 's topic is TRANSACTION operations. You can test many concepts with running multiple connections in SQL Server management studio. This article will talk about the type of locks, consistency and update operations. if you have large tables, some data modification statements may take time and block others. You will learn how to read data with different level of consistency and durability.
Before reading more about transaction levels, you need to understand that write will block read operations depending on the lock. Transactions can block other queries and create deadlocks, so you should test your queries and monitor locks for new stored procs.
Transactions have four basic properties: All-Or-Nothing, Consistency,Isolation, and Durability.
All-Or-Nothing(Atomicity): You should keep transactions compact and one unit operation. If the system fails before committing the code, system will rollback the changes automatically. Some errors are not severe enough for automatic rollback such as lock expiration time-out, key violation. You can add your Try/Catch blocks to decide for a rollback. You can also check @@TRANCOUNT to find out if there is any open transactions.
Consistency: At the end of the transaction, you may have your new and valid data accepted or rollback to original state.You can control the consistency of the data with different lock levels at resources.
Isolation: Before the data is committed or rollback to the original state , It is kept in isolation and not accessible to other transactions. You can control the lock level for each resource in the database. Type of Lock status defines your consistency for different levels of acces. You will see in the examples.
Durability: The transaction is considered durable after commit instruction is written to the transaction log on disk. When system restarts it can check transaction logs, to apply committed changes if it is not recorded in data portion.
Each individual INSERT, DELETE, UPDATE statement is an individual transaction and committed automatically without rollback. You can also use those statements within begin transaction and commit transaction to check for rollback state.
--TIP: ROLLBACK statement may return the data to its previous state, but it may not reset your identity column seed values.
LOCKS: Lock settings help you to modify the resources with the level of customized consistency from your transaction. When you try to modify data, your transaction asks for an exclusive lock on the data resource, if it is granted, it will keep the lock until the end of transaction. Only one exclusive lock is available at that resource and other request will wait for the end of the transaction. When you read the data, server asks for a shared lock and it does not place shared lock over exclusive. We will go into details of these locks, but it will help you if you can see list of locks in your database.
You can lock Row, Page, Object, Database and other type of resources. Different than your main lock type, SQL server add intent locks at higher level than your locked resource. If your transaction is using exclusive lock at the row level, intent locks will be placed at the page level and the table level.
You can query the current locks and waiting request at your server with the following query:
 Figure-1: Locks
Figure-1: Locks
You don't see any exclusive request right now in the figure above. We have Shared locks (S) granted. If you run the following query at your Adventureworks Db, you will see the list of locks at different levels. < I assume you have that from MS SQL Samples.>
 Figure: Our uncommitted transaction is showing X (Exclusive) lock at the row key.
Figure: Our uncommitted transaction is showing X (Exclusive) lock at the row key.
Since we have foreign key relations to other tables, server will automatically add shared intent (IS) locks to those tables. We have the Exclusive intent (IX) lock at the Product table and Page resource. Our row key has an exclusive lock (X) from SPID-56. This SPID is at the bottom of the query page. Each query page will have an unique SPID. If you run another query from a new query window, we can exercise wait blocks.
Run this query at another query page and check waiting processes again with sys.dm_tran_locks:
 Figure: Waiting list shows status WAIT for our query
Figure: Waiting list shows status WAIT for our query
My new query page has SPID of 59 and previous page has SPID of 56. You may different numbers in your system. Process-59 is waiting for the resource to lock for Shared mode. Since process-56 locked this row for an EXCLUSIVE lock, Shared lock will not be applied over that.
In simple terms, you don't get shared lock when another transaction is holding an exclusive lock. You can have multiple shared locks as you might guess. If you really want to read this row before uncommitted, you can set isolation level to READ UNCOMMITTED.
Open another query window and type this:
This query will read this row immediately without waiting for the commitment of the transaction. If you rollback the transaction or do some other modifications to this data at the same transaction, other query result will be INCONSISTENT.
NOLOCK is same as specifiying "READ UNCOMMITTED". If you run this query, you will get uncommited data without waiting for the resource:
You can specify READ COMMITTED, which is default for select statements, to read with shared lock. It will show you the data after update statements happen. To see what happens with READ COMMITTED option, we will begin transaction and not commit for our select statement. For this test, commit previous queries.
Ok, now we will see only shared lock for this resource as shown in the figure below.

Duration of this lock is important. Reader use shared lock for "READ COMMITTED" state until it is finished with this resource. It is not going to keep this lock until the end of the transaction. You may get inconsistent results if another transaction modify your data in between your reads, because you are not keeping shared lock untill the end of your transaction.
Now, even if we have this shared lock, we can update our data from another page while we are reading committed data. Within this transaction, you can read different commits. It does not prevent other trans to make commits. If you read balance for an account the beginning and do some calculations while holding this trans, another trans can update that balance. Your calculations will be wrong because it was based on previously committed balance. It does not prevent updates from other transactions.
If you want to read data and make sure that others do not change the values in between your reads, you can specify "REPEATABLE READ" isolation level.
When we read this record, we are blocking updates to this row within different read intervals in our transaction.
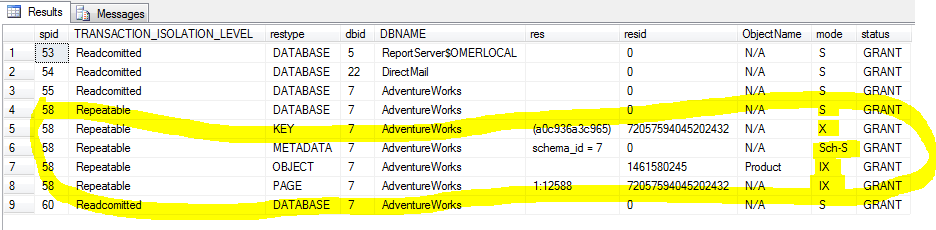 Figure: Repeatable read will add more locks to block update to this row.
Figure: Repeatable read will add more locks to block update to this row.
Other users may insert new rows even if you have "REPEATABLE READ" lock. This may change your reader output and result in inconsistent data. If you are querying top products ordered by id, you will not get consistent result. You can use SERIALIZABLE LOCK to prevent that.
SERIALIZABLE LOCK: You can lock row insert operations with serializable lock. This will prevent insert operations on your resource while you were reading it with this lock option.
Snapshot Isolation Levels
If you enable any of the snapshot based isolation levels, DELETE and UPDATE statements will copy the row before the change at resource to the "tempdb". SELECT statements will have better performance , but Modifications will be slower. Readers using snapshot level isolations will not use shared locks, so they don't need to wait for the resource. You need to turn on this option if you want to use it.
With the Snapshot isolation, reader will check the last committed version of the resource, so it is doing row versioning.
When you use Snapshot level access, you request last committed version of the resource.
This query will checkout the latest committed row data and if you start another transaction after this statement to change same rowdata and committed, you will still read from your version.
Now to test this, first open a new query window and run this query. It is reading from last committed row.
You will see latest committed product-2.
Now, Open an another window and run QUERY2. It will run that immediately without waiting. If you go back to other page and run only select statement in QUERY1, you will not see the updated price. Because we are still using previous version of the row. If you commit the transaction at QUERY1 and run it again, you will see the changes.
If you want to read latest data within your transaction, you can use "READ COMMITTED SNAPSHOT" isolation level. Readers will not use shared locks, and do not need to wait within this transaction. They will get latest version of the data. You need to set READ_COMMITTED_SNAPSHOT flag to ON to use this.
Table: Properties of different lock types within a transaction
DEADLOCK: Transaction queries may block each other if they ask for same resource with high level access. SQL server detects the deadlock and rollback the transaction which has lower amount of work.
If you want to see blocking and waiting resources with their sql text, you can run next query. You can add more information from sys.dm_exec_connections, sys.dm_exec_sessions, sys.dm_exec_requests, and system function to get sql-text( sys.dm_exec_sql_text).
If you are not comfortable with cross apply and CTE type tables, you can check articles about that from my blog.
==================SUMMARY:====================================
1. Default request is a shared lock for SELECT statements and they wait for the resource if it is locked as "Exclusive" for modifications.
2. You can read uncommitted data:: select <...> fromwith(NOLOCK) ::-> will give you uncommitted dirty data.
3. Server adds intent locks at higher level of the resource to make quick checks for resource state.
4. READ MORE from MSDN website if you are curious about LOCKS and Transactions
5. Waiting and blocking sessions may change, so you need to be careful if you want to kill a process. (You can kill the process like: KILL 52 (52 is SPID). If you kill the process before it finishes the transaction, system may rollback the changes. You need to check details on that. It might not do a good job if it is a long transaction.
6. Keep Transactions as simple as possible to reduce deadlocks and wait. It is best if your unit of work is small.
Before reading more about transaction levels, you need to understand that write will block read operations depending on the lock. Transactions can block other queries and create deadlocks, so you should test your queries and monitor locks for new stored procs.
Transactions have four basic properties: All-Or-Nothing, Consistency,Isolation, and Durability.
All-Or-Nothing(Atomicity): You should keep transactions compact and one unit operation. If the system fails before committing the code, system will rollback the changes automatically. Some errors are not severe enough for automatic rollback such as lock expiration time-out, key violation. You can add your Try/Catch blocks to decide for a rollback. You can also check @@TRANCOUNT to find out if there is any open transactions.
print 'Current Trans Ccount: ' + cast( @@TRANCOUNT as varchar(50))
Consistency: At the end of the transaction, you may have your new and valid data accepted or rollback to original state.You can control the consistency of the data with different lock levels at resources.
LOCKS: Lock settings help you to modify the resources with the level of customized consistency from your transaction. When you try to modify data, your transaction asks for an exclusive lock on the data resource, if it is granted, it will keep the lock until the end of transaction. Only one exclusive lock is available at that resource and other request will wait for the end of the transaction. When you read the data, server asks for a shared lock and it does not place shared lock over exclusive. We will go into details of these locks, but it will help you if you can see list of locks in your database.
You can query the current locks and waiting request at your server with the following query:
--QUERY for all sessions SELECT request_session_id AS spid, resource_type AS restype, resource_database_id AS dbid, DB_NAME(resource_database_id) as DBNAME, resource_description AS res, resource_associated_entity_id AS resid, CASE when resource_type = 'OBJECT' then OBJECT_NAME( resource_associated_entity_id) ELSE 'N/A' END as ObjectName, request_mode AS mode, request_status AS status FROM sys.dm_tran_locks order by spid, restype;
You don't see any exclusive request right now in the figure above. We have Shared locks (S) granted. If you run the following query at your Adventureworks Db, you will see the list of locks at different levels. < I assume you have that from MS SQL Samples.>
BEGIN TRAN; UPDATE Production.Product SET ListPrice = 0.15 where productid =4 --Commit tran; --Commit this later. We want to see the current request. print 'Current Trans Ccount: ' + cast( @@TRANCOUNT as varchar(50))
Since we have foreign key relations to other tables, server will automatically add shared intent (IS) locks to those tables. We have the Exclusive intent (IX) lock at the Product table and Page resource. Our row key has an exclusive lock (X) from SPID-56. This SPID is at the bottom of the query page. Each query page will have an unique SPID. If you run another query from a new query window, we can exercise wait blocks.
Run this query at another query page and check waiting processes again with sys.dm_tran_locks:
SELECT * from production.product where ProductID = 4;
My new query page has SPID of 59 and previous page has SPID of 56. You may different numbers in your system. Process-59 is waiting for the resource to lock for Shared mode. Since process-56 locked this row for an EXCLUSIVE lock, Shared lock will not be applied over that.
In simple terms, you don't get shared lock when another transaction is holding an exclusive lock. You can have multiple shared locks as you might guess. If you really want to read this row before uncommitted, you can set isolation level to READ UNCOMMITTED.
Open another query window and type this:
SET transaction isolation level read uncommitted; SELECT * from production.product where ProductID = 4;
This query will read this row immediately without waiting for the commitment of the transaction. If you rollback the transaction or do some other modifications to this data at the same transaction, other query result will be INCONSISTENT.
NOLOCK is same as specifiying "READ UNCOMMITTED". If you run this query, you will get uncommited data without waiting for the resource:
SELECT * from production.product with (nolock )
where ProductID = 4;
You can specify READ COMMITTED, which is default for select statements, to read with shared lock. It will show you the data after update statements happen. To see what happens with READ COMMITTED option, we will begin transaction and not commit for our select statement. For this test, commit previous queries.
SET TRANSACTION ISOLATION LEVEL READ committed;
BEGIN TRAN;
select * from production.product
where ProductID = 4
Ok, now we will see only shared lock for this resource as shown in the figure below.

Duration of this lock is important. Reader use shared lock for "READ COMMITTED" state until it is finished with this resource. It is not going to keep this lock until the end of the transaction. You may get inconsistent results if another transaction modify your data in between your reads, because you are not keeping shared lock untill the end of your transaction.
Now, even if we have this shared lock, we can update our data from another page while we are reading committed data. Within this transaction, you can read different commits. It does not prevent other trans to make commits. If you read balance for an account the beginning and do some calculations while holding this trans, another trans can update that balance. Your calculations will be wrong because it was based on previously committed balance. It does not prevent updates from other transactions.
If you want to read data and make sure that others do not change the values in between your reads, you can specify "REPEATABLE READ" isolation level.
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ; BEGIN TRAN; select * from production.product where ProductID = 4;
When we read this record, we are blocking updates to this row within different read intervals in our transaction.
Other users may insert new rows even if you have "REPEATABLE READ" lock. This may change your reader output and result in inconsistent data. If you are querying top products ordered by id, you will not get consistent result. You can use SERIALIZABLE LOCK to prevent that.
SERIALIZABLE LOCK: You can lock row insert operations with serializable lock. This will prevent insert operations on your resource while you were reading it with this lock option.
Snapshot Isolation Levels
If you enable any of the snapshot based isolation levels, DELETE and UPDATE statements will copy the row before the change at resource to the "tempdb". SELECT statements will have better performance , but Modifications will be slower. Readers using snapshot level isolations will not use shared locks, so they don't need to wait for the resource. You need to turn on this option if you want to use it.
With the Snapshot isolation, reader will check the last committed version of the resource, so it is doing row versioning.
When you use Snapshot level access, you request last committed version of the resource.
SET TRANSACTION ISOLATION LEVEL SNAPSOT; BEGIN TRAN; select * from production.product where ProductID = 4
This query will checkout the latest committed row data and if you start another transaction after this statement to change same rowdata and committed, you will still read from your version.
Now to test this, first open a new query window and run this query. It is reading from last committed row.
--QUERY1: Alter database adventureworks set allow_snapshot_isolation on; SET TRANSACTION ISOLATION LEVEL snapshot BEGIN TRAN; select * from Production.Product where ProductID = 2; --Commit TRAN --commit later
You will see latest committed product-2.
Now, Open an another window and run QUERY2. It will run that immediately without waiting. If you go back to other page and run only select statement in QUERY1, you will not see the updated price. Because we are still using previous version of the row. If you commit the transaction at QUERY1 and run it again, you will see the changes.
--QUERY2: UPDATE Production.Product SET ListPrice = 0.35 where productid =2;
If you want to read latest data within your transaction, you can use "READ COMMITTED SNAPSHOT" isolation level. Readers will not use shared locks, and do not need to wait within this transaction. They will get latest version of the data. You need to set READ_COMMITTED_SNAPSHOT flag to ON to use this.
| Lock TYPE | Uncommitted Data | Consistency ISSUE within current TRANS | RESTRICT Updates within current TRANS | RESTRICT INSERT within current TRANS | DETECT UPDATE CONFLICTS within current TRANS | ROW VERSIONs | Holds Lock to end of TRANS |
| READ UNCOMMITTED | Yes | Yes | No | No | No | No | Lowest level |
| READ COMMITTED | No | Yes | No | No | No | No | NO |
| REPEATABLE READ | No | No | Yes | No | No,but (DEADLOCK) | No | YES |
| SERIALIZABLE | No | No | Yes | Yes | No, but (DEADLOCK) | No | Yes |
| READ COMMITTED SNAPSHOT | No | Yes | No | No | No | Yes | – |
| SNAPSHOT | No | No | YES | YES | YES (Fails transaction) | YES | – |
Table: Properties of different lock types within a transaction
DEADLOCK: Transaction queries may block each other if they ask for same resource with high level access. SQL server detects the deadlock and rollback the transaction which has lower amount of work.
If you want to see blocking and waiting resources with their sql text, you can run next query. You can add more information from sys.dm_exec_connections, sys.dm_exec_sessions, sys.dm_exec_requests, and system function to get sql-text( sys.dm_exec_sql_text).
WITH CTE as --THIS IS a table expression ( SELECT request_session_id AS spid, resource_type AS restype, resource_database_id AS dbid, DB_NAME(resource_database_id) as DBNAME, resource_description AS res, resource_associated_entity_id AS resid, CASE when resource_type = 'OBJECT' then OBJECT_NAME( resource_associated_entity_id) ELSE 'N/A' END as ObjectName, request_mode AS mode, request_status AS status FROM sys.dm_tran_locks ) select sc.session_id as WAITINGSESSIONID, BLOCKS.spid as FirstBLOCKINGID, mn.DBNAME,mn.mode as WAITingMODE, (select text from sys.dm_exec_sql_text( sc.most_recent_sql_handle) ) as SQLWAITING, (select text from sys.dm_exec_sql_text( BLOCKS.most_recent_sql_handle) ) as SQLBLOCKING from CTE mn join sys.dm_exec_connections sc on mn.spid = sc.session_id cross apply ( select top 1 * from CTE sub join sys.dm_exec_connections sc on sub.spid = sc.session_id where sub.res = mn.res and sub.status = 'GRANT' ) as BLOCKS where mn.status = 'WAIT' ;
If you are not comfortable with cross apply and CTE type tables, you can check articles about that from my blog.
==================SUMMARY:====================================
1. Default request is a shared lock for SELECT statements and they wait for the resource if it is locked as "Exclusive" for modifications.
2. You can read uncommitted data:: select <...> from
Sunday, April 25, 2010
How to find start and end of the month as Datetime in SQL
While waiting at McDonalds, I decide to make a small post.
Some examples to get the start and the end of the month as datetime field.
Declare @mysearch datetime
Declare @StartDate datetime
Declare @EndDate datetime
set @mysearch = '20100401 00:00:01';
--First day of the month as Datetime field
set @StartDate = dateadd(ms,0,DATEADD(mm, DATEDIFF(m,0,getdate() ), 0));
--Last day of the month as Datetime field
set @EndDate = dateadd(ms,0,DATEADD(mm, DATEDIFF(m,0,getdate() )+1, 0)) ;
if (@mysearch >= @StartDate and @mysearch < @EndDate)
print 'Between this datetime' else print 'Not Between this datetime'
--In this example,we are using DATEDIFF, DATEADD, and GetDATE() functions.
DATEDIFF ( datepart , startdate , enddate ): You can set the datepart from nanosecond to year. It basically gives you the difference between startdate and enddate.
::To find difference in years:
SELECT DATEDIFF(year, '2003-01-01', '2006-01-01'); --> will give you 3 as a difference. You can specify startdate and enddate in different formats.
::TO find difference in hrs:
SELECT DATEDIFF(HOUR, '2010-04-22 22:59:59.9999999'
, '2010-04-23 00:00:00.0000000');-->this will give you 2 hrs.
Now if you run this::
SELECT DATEDIFF(HOUR, '2010-04-22 23:59:59.9999999'
, '2010-04-23 00:00:00.0000000');-->You will get 1hr difference. If you run for minutes, you will get 1 minute. As you might guess, it will also give 1 for difference in days.
::Referenced Datetime
In our first example we used 0 as our reference datetime field. You will still get the same result even if you set something else. We are simply taking difference and adding over the referenced datetime.
declare @REFERENCE datetime
set @REFERENCE = '20100401'
select dateadd(ms,0,DATEADD(mm, DATEDIFF(m,@REFERENCE,getdate() )+1, @REFERENCE))
If you specify this @REFERENCE as '20100401 10:12:12', you will get time field in your result. Output: 2010-05-01 10:12:12.000
Using same technique we can find many other datetime fields::
::LAST DAY OF THE PREVIOUS YEAR as Datetime
select dateadd(ms, -3, DATEADD(yy, DATEDIFF( year,0,getdate() ), 0))
::FIRST DAY OF this week
select DATEADD(week, DATEDIFF(week,0,getdate() ),0);
::LAST DAY of this week
select dateadd(day,-1,DATEADD(week, DATEDIFF(week,0,getdate() )+1,0));
::Last day of this week within ms for datetime comparison
select dateadd(ms,-3,DATEADD(week, DATEDIFF(week,0,getdate() )+1,0));
::I guess you figured out how to do the other possible cases.
Some examples to get the start and the end of the month as datetime field.
Declare @mysearch datetime
Declare @StartDate datetime
Declare @EndDate datetime
set @mysearch = '20100401 00:00:01';
--First day of the month as Datetime field
set @StartDate = dateadd(ms,0,DATEADD(mm, DATEDIFF(m,0,getdate() ), 0));
--Last day of the month as Datetime field
set @EndDate = dateadd(ms,0,DATEADD(mm, DATEDIFF(m,0,getdate() )+1, 0)) ;
if (@mysearch >= @StartDate and @mysearch < @EndDate)
print 'Between this datetime' else print 'Not Between this datetime'
--In this example,we are using DATEDIFF, DATEADD, and GetDATE() functions.
DATEDIFF ( datepart , startdate , enddate ): You can set the datepart from nanosecond to year. It basically gives you the difference between startdate and enddate.
::To find difference in years:
SELECT DATEDIFF(year, '2003-01-01', '2006-01-01'); --> will give you 3 as a difference. You can specify startdate and enddate in different formats.
::TO find difference in hrs:
SELECT DATEDIFF(HOUR, '2010-04-22 22:59:59.9999999'
, '2010-04-23 00:00:00.0000000');-->this will give you 2 hrs.
Now if you run this::
SELECT DATEDIFF(HOUR, '2010-04-22 23:59:59.9999999'
, '2010-04-23 00:00:00.0000000');-->You will get 1hr difference. If you run for minutes, you will get 1 minute. As you might guess, it will also give 1 for difference in days.
::Referenced Datetime
In our first example we used 0 as our reference datetime field. You will still get the same result even if you set something else. We are simply taking difference and adding over the referenced datetime.
declare @REFERENCE datetime
set @REFERENCE = '20100401'
select dateadd(ms,0,DATEADD(mm, DATEDIFF(m,@REFERENCE,getdate() )+1, @REFERENCE))
If you specify this @REFERENCE as '20100401 10:12:12', you will get time field in your result. Output: 2010-05-01 10:12:12.000
Using same technique we can find many other datetime fields::
::LAST DAY OF THE PREVIOUS YEAR as Datetime
select dateadd(ms, -3, DATEADD(yy, DATEDIFF( year,0,getdate() ), 0))
::FIRST DAY OF this week
select DATEADD(week, DATEDIFF(week,0,getdate() ),0);
::LAST DAY of this week
select dateadd(day,-1,DATEADD(week, DATEDIFF(week,0,getdate() )+1,0));
::Last day of this week within ms for datetime comparison
select dateadd(ms,-3,DATEADD(week, DATEDIFF(week,0,getdate() )+1,0));
::I guess you figured out how to do the other possible cases.
::SQL Helpers
I will add some of the useful sql functions:
::COLUMN NAMES in a Table
select name from sys.columns
where object_id = OBJECT_ID(N'Sales.Orders');
::Information about schema views
lists the user tables in the current database along with their schema names
select table_schema, table_name, IST.TABLE_TYPE, IST.TABLE_CATALOG
from INFORMATION_SCHEMA.TABLES IST
--where TABLE_TYPE = N'Base table'
::List of tables in the database
exec sys.sp_tables;
::Waiting and Blocking Processes
Run this query at another query page and check waiting processes again with sys.dm_tran_locks
::COLUMN NAMES in a Table
select name from sys.columns
where object_id = OBJECT_ID(N'Sales.Orders');
::Information about schema views
lists the user tables in the current database along with their schema names
select table_schema, table_name, IST.TABLE_TYPE, IST.TABLE_CATALOG
from INFORMATION_SCHEMA.TABLES IST
--where TABLE_TYPE = N'Base table'
::List of tables in the database
exec sys.sp_tables;
::Waiting and Blocking Processes
SELECT
request_session_id AS spid,
resource_type AS restype,
resource_database_id AS dbid,
DB_NAME(resource_database_id) as DBNAME,
resource_description AS res,
resource_associated_entity_id AS resid,
CASE
when resource_type = 'OBJECT' then OBJECT_NAME( resource_associated_entity_id)
ELSE 'N/A'
END as ObjectName,
request_mode AS mode,
request_status AS status
FROM sys.dm_tran_locks
order by spid, restype;
Subscribe to:
Posts (Atom)