Today 's topic is TRANSACTION operations. You can test many concepts with running multiple connections in SQL Server management studio. This article will talk about the type of locks, consistency and update operations. if you have large tables, some data modification statements may take time and block others. You will learn how to read data with different level of consistency and durability.
Before reading more about transaction levels, you need to understand that write will block read operations depending on the lock. Transactions can block other queries and create deadlocks, so you should test your queries and monitor locks for new stored procs.
Transactions have four basic properties: All-Or-Nothing, Consistency,Isolation, and Durability.
All-Or-Nothing(Atomicity): You should keep transactions compact and one unit operation. If the system fails before committing the code, system will rollback the changes automatically. Some errors are not severe enough for automatic rollback such as lock expiration time-out, key violation. You can add your Try/Catch blocks to decide for a rollback. You can also check @@TRANCOUNT to find out if there is any open transactions.
Consistency: At the end of the transaction, you may have your new and valid data accepted or rollback to original state.You can control the consistency of the data with different lock levels at resources.
Isolation: Before the data is committed or rollback to the original state , It is kept in isolation and not accessible to other transactions. You can control the lock level for each resource in the database. Type of Lock status defines your consistency for different levels of acces. You will see in the examples.
Durability: The transaction is considered durable after commit instruction is written to the transaction log on disk. When system restarts it can check transaction logs, to apply committed changes if it is not recorded in data portion.
Each individual INSERT, DELETE, UPDATE statement is an individual transaction and committed automatically without rollback. You can also use those statements within begin transaction and commit transaction to check for rollback state.
--TIP: ROLLBACK statement may return the data to its previous state, but it may not reset your identity column seed values.
LOCKS: Lock settings help you to modify the resources with the level of customized consistency from your transaction. When you try to modify data, your transaction asks for an exclusive lock on the data resource, if it is granted, it will keep the lock until the end of transaction. Only one exclusive lock is available at that resource and other request will wait for the end of the transaction. When you read the data, server asks for a shared lock and it does not place shared lock over exclusive. We will go into details of these locks, but it will help you if you can see list of locks in your database.
You can lock Row, Page, Object, Database and other type of resources. Different than your main lock type, SQL server add intent locks at higher level than your locked resource. If your transaction is using exclusive lock at the row level, intent locks will be placed at the page level and the table level.
You can query the current locks and waiting request at your server with the following query:
 Figure-1: Locks
Figure-1: Locks
You don't see any exclusive request right now in the figure above. We have Shared locks (S) granted. If you run the following query at your Adventureworks Db, you will see the list of locks at different levels. < I assume you have that from MS SQL Samples.>
 Figure: Our uncommitted transaction is showing X (Exclusive) lock at the row key.
Figure: Our uncommitted transaction is showing X (Exclusive) lock at the row key.
Since we have foreign key relations to other tables, server will automatically add shared intent (IS) locks to those tables. We have the Exclusive intent (IX) lock at the Product table and Page resource. Our row key has an exclusive lock (X) from SPID-56. This SPID is at the bottom of the query page. Each query page will have an unique SPID. If you run another query from a new query window, we can exercise wait blocks.
Run this query at another query page and check waiting processes again with sys.dm_tran_locks:
 Figure: Waiting list shows status WAIT for our query
Figure: Waiting list shows status WAIT for our query
My new query page has SPID of 59 and previous page has SPID of 56. You may different numbers in your system. Process-59 is waiting for the resource to lock for Shared mode. Since process-56 locked this row for an EXCLUSIVE lock, Shared lock will not be applied over that.
In simple terms, you don't get shared lock when another transaction is holding an exclusive lock. You can have multiple shared locks as you might guess. If you really want to read this row before uncommitted, you can set isolation level to READ UNCOMMITTED.
Open another query window and type this:
This query will read this row immediately without waiting for the commitment of the transaction. If you rollback the transaction or do some other modifications to this data at the same transaction, other query result will be INCONSISTENT.
NOLOCK is same as specifiying "READ UNCOMMITTED". If you run this query, you will get uncommited data without waiting for the resource:
You can specify READ COMMITTED, which is default for select statements, to read with shared lock. It will show you the data after update statements happen. To see what happens with READ COMMITTED option, we will begin transaction and not commit for our select statement. For this test, commit previous queries.
Ok, now we will see only shared lock for this resource as shown in the figure below.

Duration of this lock is important. Reader use shared lock for "READ COMMITTED" state until it is finished with this resource. It is not going to keep this lock until the end of the transaction. You may get inconsistent results if another transaction modify your data in between your reads, because you are not keeping shared lock untill the end of your transaction.
Now, even if we have this shared lock, we can update our data from another page while we are reading committed data. Within this transaction, you can read different commits. It does not prevent other trans to make commits. If you read balance for an account the beginning and do some calculations while holding this trans, another trans can update that balance. Your calculations will be wrong because it was based on previously committed balance. It does not prevent updates from other transactions.
If you want to read data and make sure that others do not change the values in between your reads, you can specify "REPEATABLE READ" isolation level.
When we read this record, we are blocking updates to this row within different read intervals in our transaction.
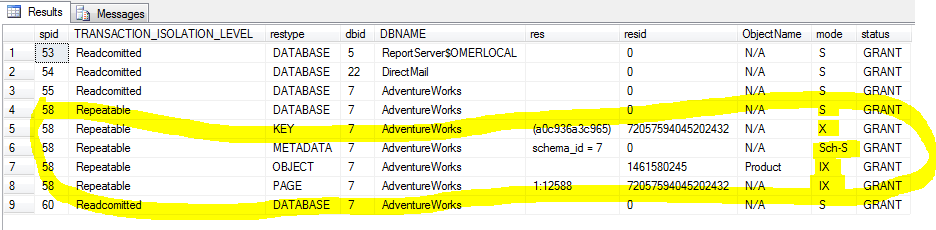 Figure: Repeatable read will add more locks to block update to this row.
Figure: Repeatable read will add more locks to block update to this row.
Other users may insert new rows even if you have "REPEATABLE READ" lock. This may change your reader output and result in inconsistent data. If you are querying top products ordered by id, you will not get consistent result. You can use SERIALIZABLE LOCK to prevent that.
SERIALIZABLE LOCK: You can lock row insert operations with serializable lock. This will prevent insert operations on your resource while you were reading it with this lock option.
Snapshot Isolation Levels
If you enable any of the snapshot based isolation levels, DELETE and UPDATE statements will copy the row before the change at resource to the "tempdb". SELECT statements will have better performance , but Modifications will be slower. Readers using snapshot level isolations will not use shared locks, so they don't need to wait for the resource. You need to turn on this option if you want to use it.
With the Snapshot isolation, reader will check the last committed version of the resource, so it is doing row versioning.
When you use Snapshot level access, you request last committed version of the resource.
This query will checkout the latest committed row data and if you start another transaction after this statement to change same rowdata and committed, you will still read from your version.
Now to test this, first open a new query window and run this query. It is reading from last committed row.
You will see latest committed product-2.
Now, Open an another window and run QUERY2. It will run that immediately without waiting. If you go back to other page and run only select statement in QUERY1, you will not see the updated price. Because we are still using previous version of the row. If you commit the transaction at QUERY1 and run it again, you will see the changes.
If you want to read latest data within your transaction, you can use "READ COMMITTED SNAPSHOT" isolation level. Readers will not use shared locks, and do not need to wait within this transaction. They will get latest version of the data. You need to set READ_COMMITTED_SNAPSHOT flag to ON to use this.
Table: Properties of different lock types within a transaction
DEADLOCK: Transaction queries may block each other if they ask for same resource with high level access. SQL server detects the deadlock and rollback the transaction which has lower amount of work.
If you want to see blocking and waiting resources with their sql text, you can run next query. You can add more information from sys.dm_exec_connections, sys.dm_exec_sessions, sys.dm_exec_requests, and system function to get sql-text( sys.dm_exec_sql_text).
If you are not comfortable with cross apply and CTE type tables, you can check articles about that from my blog.
==================SUMMARY:====================================
1. Default request is a shared lock for SELECT statements and they wait for the resource if it is locked as "Exclusive" for modifications.
2. You can read uncommitted data:: select <...> fromwith(NOLOCK) ::-> will give you uncommitted dirty data.
3. Server adds intent locks at higher level of the resource to make quick checks for resource state.
4. READ MORE from MSDN website if you are curious about LOCKS and Transactions
5. Waiting and blocking sessions may change, so you need to be careful if you want to kill a process. (You can kill the process like: KILL 52 (52 is SPID). If you kill the process before it finishes the transaction, system may rollback the changes. You need to check details on that. It might not do a good job if it is a long transaction.
6. Keep Transactions as simple as possible to reduce deadlocks and wait. It is best if your unit of work is small.
Before reading more about transaction levels, you need to understand that write will block read operations depending on the lock. Transactions can block other queries and create deadlocks, so you should test your queries and monitor locks for new stored procs.
Transactions have four basic properties: All-Or-Nothing, Consistency,Isolation, and Durability.
All-Or-Nothing(Atomicity): You should keep transactions compact and one unit operation. If the system fails before committing the code, system will rollback the changes automatically. Some errors are not severe enough for automatic rollback such as lock expiration time-out, key violation. You can add your Try/Catch blocks to decide for a rollback. You can also check @@TRANCOUNT to find out if there is any open transactions.
print 'Current Trans Ccount: ' + cast( @@TRANCOUNT as varchar(50))
Consistency: At the end of the transaction, you may have your new and valid data accepted or rollback to original state.You can control the consistency of the data with different lock levels at resources.
LOCKS: Lock settings help you to modify the resources with the level of customized consistency from your transaction. When you try to modify data, your transaction asks for an exclusive lock on the data resource, if it is granted, it will keep the lock until the end of transaction. Only one exclusive lock is available at that resource and other request will wait for the end of the transaction. When you read the data, server asks for a shared lock and it does not place shared lock over exclusive. We will go into details of these locks, but it will help you if you can see list of locks in your database.
You can query the current locks and waiting request at your server with the following query:
--QUERY for all sessions SELECT request_session_id AS spid, resource_type AS restype, resource_database_id AS dbid, DB_NAME(resource_database_id) as DBNAME, resource_description AS res, resource_associated_entity_id AS resid, CASE when resource_type = 'OBJECT' then OBJECT_NAME( resource_associated_entity_id) ELSE 'N/A' END as ObjectName, request_mode AS mode, request_status AS status FROM sys.dm_tran_locks order by spid, restype;
You don't see any exclusive request right now in the figure above. We have Shared locks (S) granted. If you run the following query at your Adventureworks Db, you will see the list of locks at different levels. < I assume you have that from MS SQL Samples.>
BEGIN TRAN; UPDATE Production.Product SET ListPrice = 0.15 where productid =4 --Commit tran; --Commit this later. We want to see the current request. print 'Current Trans Ccount: ' + cast( @@TRANCOUNT as varchar(50))
Since we have foreign key relations to other tables, server will automatically add shared intent (IS) locks to those tables. We have the Exclusive intent (IX) lock at the Product table and Page resource. Our row key has an exclusive lock (X) from SPID-56. This SPID is at the bottom of the query page. Each query page will have an unique SPID. If you run another query from a new query window, we can exercise wait blocks.
Run this query at another query page and check waiting processes again with sys.dm_tran_locks:
SELECT * from production.product where ProductID = 4;
My new query page has SPID of 59 and previous page has SPID of 56. You may different numbers in your system. Process-59 is waiting for the resource to lock for Shared mode. Since process-56 locked this row for an EXCLUSIVE lock, Shared lock will not be applied over that.
In simple terms, you don't get shared lock when another transaction is holding an exclusive lock. You can have multiple shared locks as you might guess. If you really want to read this row before uncommitted, you can set isolation level to READ UNCOMMITTED.
Open another query window and type this:
SET transaction isolation level read uncommitted; SELECT * from production.product where ProductID = 4;
This query will read this row immediately without waiting for the commitment of the transaction. If you rollback the transaction or do some other modifications to this data at the same transaction, other query result will be INCONSISTENT.
NOLOCK is same as specifiying "READ UNCOMMITTED". If you run this query, you will get uncommited data without waiting for the resource:
SELECT * from production.product with (nolock )
where ProductID = 4;
You can specify READ COMMITTED, which is default for select statements, to read with shared lock. It will show you the data after update statements happen. To see what happens with READ COMMITTED option, we will begin transaction and not commit for our select statement. For this test, commit previous queries.
SET TRANSACTION ISOLATION LEVEL READ committed;
BEGIN TRAN;
select * from production.product
where ProductID = 4
Ok, now we will see only shared lock for this resource as shown in the figure below.

Duration of this lock is important. Reader use shared lock for "READ COMMITTED" state until it is finished with this resource. It is not going to keep this lock until the end of the transaction. You may get inconsistent results if another transaction modify your data in between your reads, because you are not keeping shared lock untill the end of your transaction.
Now, even if we have this shared lock, we can update our data from another page while we are reading committed data. Within this transaction, you can read different commits. It does not prevent other trans to make commits. If you read balance for an account the beginning and do some calculations while holding this trans, another trans can update that balance. Your calculations will be wrong because it was based on previously committed balance. It does not prevent updates from other transactions.
If you want to read data and make sure that others do not change the values in between your reads, you can specify "REPEATABLE READ" isolation level.
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ; BEGIN TRAN; select * from production.product where ProductID = 4;
When we read this record, we are blocking updates to this row within different read intervals in our transaction.
Other users may insert new rows even if you have "REPEATABLE READ" lock. This may change your reader output and result in inconsistent data. If you are querying top products ordered by id, you will not get consistent result. You can use SERIALIZABLE LOCK to prevent that.
SERIALIZABLE LOCK: You can lock row insert operations with serializable lock. This will prevent insert operations on your resource while you were reading it with this lock option.
Snapshot Isolation Levels
If you enable any of the snapshot based isolation levels, DELETE and UPDATE statements will copy the row before the change at resource to the "tempdb". SELECT statements will have better performance , but Modifications will be slower. Readers using snapshot level isolations will not use shared locks, so they don't need to wait for the resource. You need to turn on this option if you want to use it.
With the Snapshot isolation, reader will check the last committed version of the resource, so it is doing row versioning.
When you use Snapshot level access, you request last committed version of the resource.
SET TRANSACTION ISOLATION LEVEL SNAPSOT; BEGIN TRAN; select * from production.product where ProductID = 4
This query will checkout the latest committed row data and if you start another transaction after this statement to change same rowdata and committed, you will still read from your version.
Now to test this, first open a new query window and run this query. It is reading from last committed row.
--QUERY1: Alter database adventureworks set allow_snapshot_isolation on; SET TRANSACTION ISOLATION LEVEL snapshot BEGIN TRAN; select * from Production.Product where ProductID = 2; --Commit TRAN --commit later
You will see latest committed product-2.
Now, Open an another window and run QUERY2. It will run that immediately without waiting. If you go back to other page and run only select statement in QUERY1, you will not see the updated price. Because we are still using previous version of the row. If you commit the transaction at QUERY1 and run it again, you will see the changes.
--QUERY2: UPDATE Production.Product SET ListPrice = 0.35 where productid =2;
If you want to read latest data within your transaction, you can use "READ COMMITTED SNAPSHOT" isolation level. Readers will not use shared locks, and do not need to wait within this transaction. They will get latest version of the data. You need to set READ_COMMITTED_SNAPSHOT flag to ON to use this.
| Lock TYPE | Uncommitted Data | Consistency ISSUE within current TRANS | RESTRICT Updates within current TRANS | RESTRICT INSERT within current TRANS | DETECT UPDATE CONFLICTS within current TRANS | ROW VERSIONs | Holds Lock to end of TRANS |
| READ UNCOMMITTED | Yes | Yes | No | No | No | No | Lowest level |
| READ COMMITTED | No | Yes | No | No | No | No | NO |
| REPEATABLE READ | No | No | Yes | No | No,but (DEADLOCK) | No | YES |
| SERIALIZABLE | No | No | Yes | Yes | No, but (DEADLOCK) | No | Yes |
| READ COMMITTED SNAPSHOT | No | Yes | No | No | No | Yes | – |
| SNAPSHOT | No | No | YES | YES | YES (Fails transaction) | YES | – |
Table: Properties of different lock types within a transaction
DEADLOCK: Transaction queries may block each other if they ask for same resource with high level access. SQL server detects the deadlock and rollback the transaction which has lower amount of work.
If you want to see blocking and waiting resources with their sql text, you can run next query. You can add more information from sys.dm_exec_connections, sys.dm_exec_sessions, sys.dm_exec_requests, and system function to get sql-text( sys.dm_exec_sql_text).
WITH CTE as --THIS IS a table expression ( SELECT request_session_id AS spid, resource_type AS restype, resource_database_id AS dbid, DB_NAME(resource_database_id) as DBNAME, resource_description AS res, resource_associated_entity_id AS resid, CASE when resource_type = 'OBJECT' then OBJECT_NAME( resource_associated_entity_id) ELSE 'N/A' END as ObjectName, request_mode AS mode, request_status AS status FROM sys.dm_tran_locks ) select sc.session_id as WAITINGSESSIONID, BLOCKS.spid as FirstBLOCKINGID, mn.DBNAME,mn.mode as WAITingMODE, (select text from sys.dm_exec_sql_text( sc.most_recent_sql_handle) ) as SQLWAITING, (select text from sys.dm_exec_sql_text( BLOCKS.most_recent_sql_handle) ) as SQLBLOCKING from CTE mn join sys.dm_exec_connections sc on mn.spid = sc.session_id cross apply ( select top 1 * from CTE sub join sys.dm_exec_connections sc on sub.spid = sc.session_id where sub.res = mn.res and sub.status = 'GRANT' ) as BLOCKS where mn.status = 'WAIT' ;
If you are not comfortable with cross apply and CTE type tables, you can check articles about that from my blog.
==================SUMMARY:====================================
1. Default request is a shared lock for SELECT statements and they wait for the resource if it is locked as "Exclusive" for modifications.
2. You can read uncommitted data:: select <...> from